playground
缓存
缓存的典型场景有以下几种。
-
对于需要复杂运算后才能得到的数据,且数据的实时性要求不高,那么就可以把计算结果事先存储在缓存中,当客户端请求该数据时只需要从缓存中读取。比如在一个定时任务中进行周期性的计算,完成计算后把结果写入缓存中。
-
对于读多写少的系统,可以把数据放到缓存中,减小数据库的压力。
缓存穿透
缓存穿透是指缓存没有起到作用,比如以下几种场景。
-
访问的数据不存在,请求会穿过缓存访问数据库,黑客利用这一点大量访问不存在的数据从而拖垮数据库。解决方法是把不存在的数据在缓存中存储一个空值,也可以按照业务规则对参数的合法性进行检查,从而挡掉一部分的恶意攻击。
-
爬虫对数据进行完整的抓取而系统只缓存了一部分数据,比如对于一个分页查询,缓存只保留了前10页的数据(热点数据),而爬虫从第1页爬到最后一页,系统就需要为大部分不常被访问的数据生成大量的缓存,浪费系统资源。这种情况下没有很好的解决方法,如果我们识别并禁止了爬虫有可能会影响SEO。
缓存雪崩
缓存雪崩是指当缓存不可用(如Redis宕机)或者大量缓存在同一时间失效,在缓存可用或被重新创建之前有大量的请求直接访问数据库,从而导致数据库压力剧增,拖垮整个系统。有以下几种常见的方案。
- 针对不同的数据设置不同的过期时间,避免大量缓存在同一时间失效。
- 当有大量线程尝试重建缓存时,利用分布式锁保证只有一个线程可以成功重建缓存,其它线程则等待缓存完成重建。也可以引入二级缓存,二级缓存的过期时间设置的比一级缓存久一些,还是用分布式锁保证只有一个线程重建一级缓存,其它线程发现锁被其它线程占用后就去读取二级缓存中的数据,可以把二级缓存看成是一级缓存的快照。
- 由额外的后台线程定时更新缓存,并且缓存的过期时间设为永久,业务线程只能从缓存读取数据,不能读取数据库也不能更新缓存。
缓存预热
在服务启动时可以用后台线程预先把相关的缓存加载到缓存系统中,而不是等到请求来临时才创建缓存。
更新策略
根据不同的缓存使用场景主要有以下几种更新策略,可以按照业务组合多种策略。
Cache-aside
Cache-aside是比较常见的策略,当请求数据时,会先从缓存中查找,如果命中则直接返回,否则查询数据库,如果数据存在那么回填到缓存中,并设置一个超时时间,其伪代码如下。
Object getObject(String key){
// 查询缓存。
Object obj = cache.get(key);
// 缓存命中则返回结果。
if (obj != null){
return obj;
}
// 缓存没有命中,则查询数据库。
obj = db.select(key);
if (obj != null){
// 如果查询结果存在,那么把查询结果放到缓存中,并设置一个过期时间。
cache.set(key, obj, expireTime);
}
return obj;
}
优点是实现起来方便;缺点是当缓存没有命中时,在高并发情况下会有大量请求达到数据库。
Write-through
Write-through策略的场景中客户端对应用的读写都是直接在缓存上进行,不会直接访问数据库,当数据写入缓存时会同步的写入数据库,其伪代码如下。
void saveObject(String key, Object object){
db.insert(object);
cache.set(key, object, expireTime);
}
优点是读取操作响应速度快,因为是从缓存中读取的;缺点是写入的时候比较慢,因为需要写数据库。
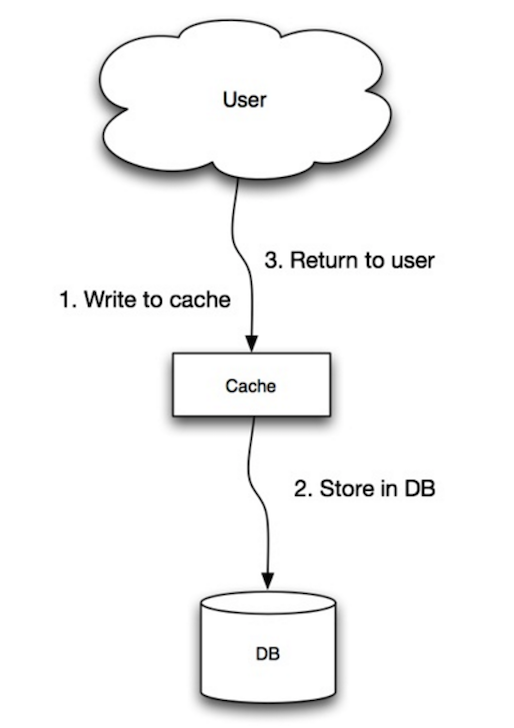
Write-behind
和Write-through策略类似,区别是Write-behind策略是异步把数据写回数据库的。优点是因为采用异步的方式同步数据,服务的响应较短;缺点是在数据同步回数据库前如果缓存挂了,那么这个时候请求是读不到数据的,就像数据丢失了。
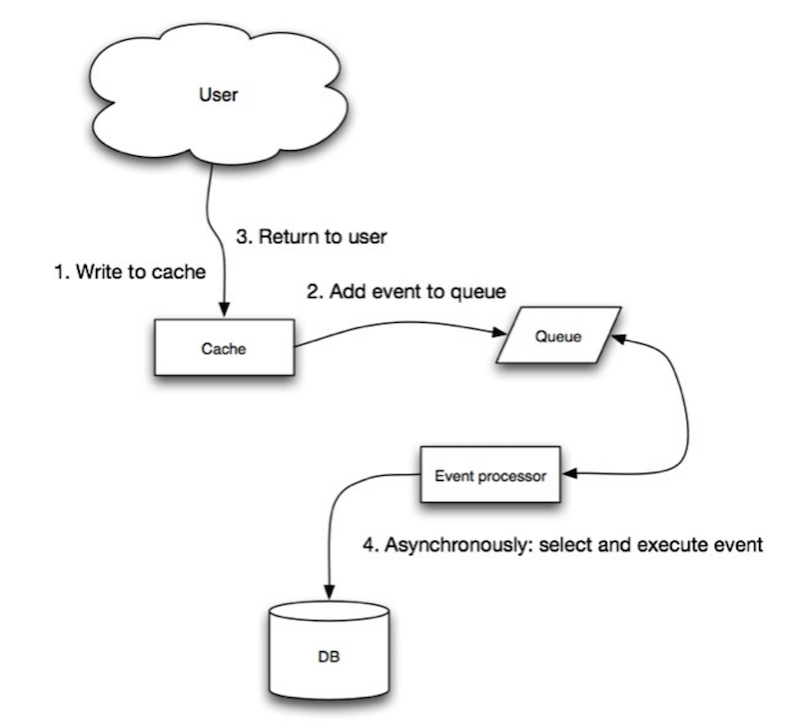
Refresh-ahead
缓存过期前由后台线程自动刷新,适用于有大量请求读取热点数据的场景。优点是不存在缓存并发的问题;缺点是难以预测哪些数据需要被缓存,也就是说难以预测哪些数据会成为热点数据。
数据一致性
对于双写数据库和缓存的情况我们需要考虑并发状态下数据一致性的问题,通常有以下几种情况。
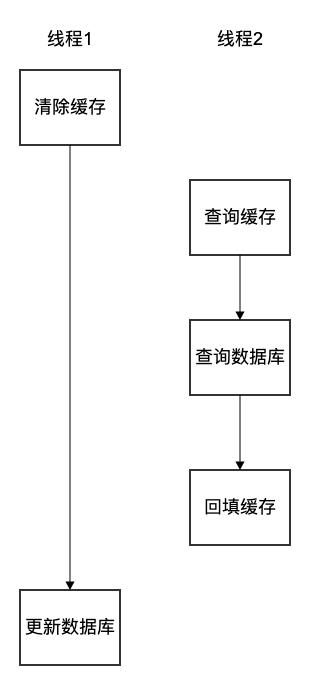
- 先清除缓存,再更新数据库。
假设有两个线程并发执行,线程1是写线程,线程2是读线程。当线程1清除缓存后,线程2的查询没有命中缓存,这时线程2会查询数据库并把结果回填缓存,这时线程1更新数据库,可以看到此时缓存和数据库中的数据是不一致的。
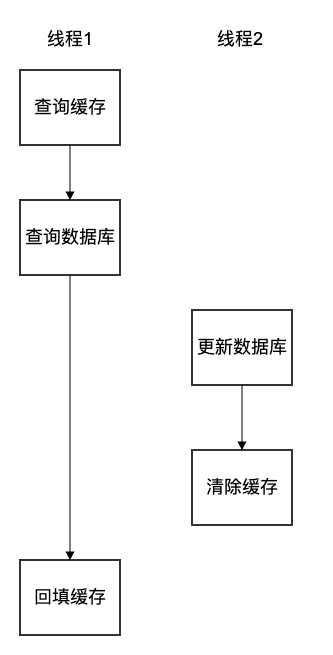
- 先更新数据库,再清除缓存
假设有两个线程并发执行,线程1是读线程,线程2是写线程。线程1查询时没有命中缓存,因此去查询数据库,在此时线程2更新了数据库并清除了缓存,线程1把线程2更新数据库之前查询到的结果回填到缓存中,此时数据是不一致的。尽管如此,依旧推荐使用这种策略,这是因为这种策略出现数据不一致的概率较低,需要满足线程2的写数据库操作比线程1的读数据库操作快才可能出现数据不一致的情况,但是通常数据库的读操作远快于写操作。
综上可以看出,保证数据一致性的关键是在更新数据库后要保证缓存是被清除的,否则缓存中的数据必然和数据库中的数据不一致。当然,我们只要对缓存设置了过期时间,通常数据都可以达到最终一致(实际上上面两种方案也都是最终一致,只是不一致的时间较短)。