playground
分布式ID生成器
生成分布式ID需要满足以下几种诉求:
- 全局唯一:生成的ID必须全局唯一,不能重复生成。
- 高性能:没有性能瓶颈。
- 高可用:生成器需要考虑各种故障场景,足够健壮。
- 易用:方便业务方接入使用,生成的ID最好具备业务含义。
- 趋势自增:对数据库写入友好。
UUID
通过各个语言自身的UUID标准库即可生成全剧唯一的ID。
- 优点:实现方式简单。
- 缺点:
- 没有业务含义。
- 没有趋势自增特性。
数据库
单数据库
使用单个数据库生成自增主键。
- 优点:实现方式简单。
- 缺点:
- 存在性能瓶颈。
- 存在单点故障。
多数据库
我们可以对上述方案扩展到多个数据库,以分散数据库的压力。为了让每个数据库生成的ID全剧唯一,需要为每个数据库设置不同的自增步长。
-- 数据库1
set @@auto_increment_offset = 1; -- 起始值
-- @@auto_increment_increment的值等于数据库的数量
set @@auto_increment_increment = 2; -- 步长
-- 数据库2
set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 2; -- 步长
- 优点:解决了单点问题。
- 缺点:不易扩展,当需要增加数据库时比较麻烦。
号段模式
通过1次请求取出一个号段范围的方式可以降低数据库的压力。
CREATE TABLE id_generator (
max_id bigint(20) NOT NULL COMMENT '当前最大id'
)
-- 每次取 new_max_id - max_id 个ID
UPDATE id_generator
SET max_id = #{new_max_id}
WHERE max_id = #{old_max_id}
Redis
通过incr命令可以获得自增的ID,和数据库方案类似。需要注意的是由于Redis的持久化特性,宕机恢复后可能存在数据丢失,因此可能生成重复的ID,解决方法是开启AOF持久化机制,对每条写命令进行持久化,缺点是生成的AOF文件较大,数据恢复时间较长。
Snowflake
Snowflake是twitter提出的分布式ID生成方案,它是一个64位长度的序列,其结构如下。
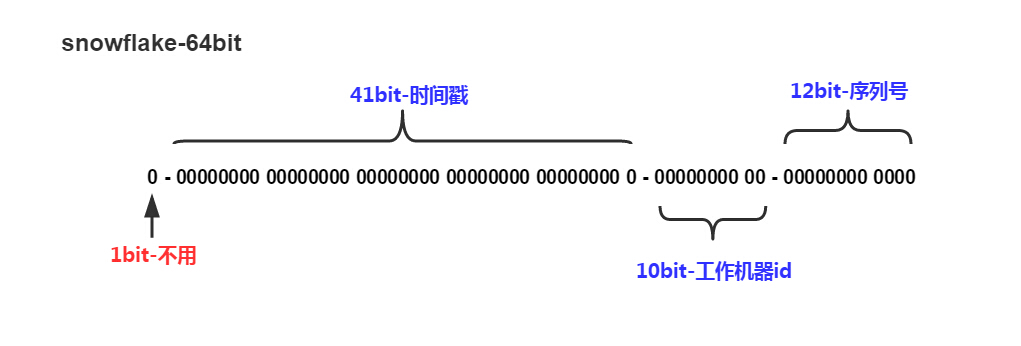
其中左起第一位永远是0,可以看作是符号位,表明序列不为负数;41位的时间戳记录的是毫秒时间,一般是当前时间减去某个固定起始时间的偏移量而不是从1970年1月1日算起,一共可以使用69年;10位机器ID可以分配给1024台机器;最后的12位序列号可以在同一毫秒内生成4096个不同的序列,如果某一毫秒下的4096个序列已经用完了,那么需要等待至下一豪秒以防止ID重复。
Snowflake的缺点是严重依赖机器时间,如果机器时间出现了回拨,就有可能生成重复的ID,解决方法是在服务启动时进行核对,如果时间回拨则启动失败,另外在运行过程中发现回拨则可以进行等待并通过监控系统上报异常。