playground
ScheduledThreadPoolExecutor
![]()
ScheduledThreadPoolExecutor是一个执行定时任务的线程池,它的类结构如下。
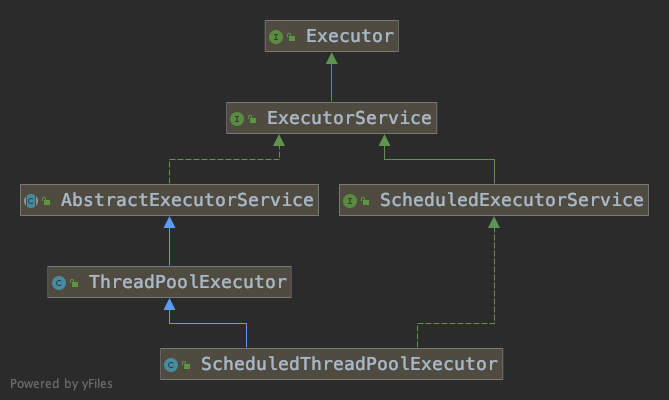
ScheduledThreadPoolExecutor(int)
从构造方法中可以看到,ScheduledThreadPoolExecutor使用了DelayedWorkQueue队列。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}
schedule(Runnable, long, TimeUnit)
schedule()方法用于延迟执行一次性的任务。
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
// 构建一个RunnableScheduledFuture对象,包含触发时间,序号等信息。
RunnableScheduledFuture<Void> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null,
triggerTime(delay, unit),
sequencer.getAndIncrement()));
delayedExecute(t);
return t;
}
private void delayedExecute(RunnableScheduledFuture<?> task) {
// 如果线程池已经关闭了,那么执行拒绝策略。
if (isShutdown())
reject(task);
else {
// 把任务放入队列中,这里的队列就是DelayedWorkQueue。
super.getQueue().add(task);
// 判断当前任务是否可以执行。
// 如果不能执行,那么尝试从队列中删除任务。
// 如果删除成功那么就把任务标为已取消。
if (!canRunInCurrentRunState(task) && remove(task))
task.cancel(false);
else
// 否则开始任务。
ensurePrestart();
}
}
boolean canRunInCurrentRunState(RunnableScheduledFuture<?> task) {
// 如果线程池没有被关闭,那么任务可以执行。
if (!isShutdown())
return true;
// 如果线程池已经进入停止状态,那么任务不能执行。
if (isStopped())
return false;
// 否则由以下两个参数决定能否执行任务。
// 默认continueExistingPeriodicTasksAfterShutdown是false,executeExistingDelayedTasksAfterShutdown是true。
return task.isPeriodic()
? continueExistingPeriodicTasksAfterShutdown
: (executeExistingDelayedTasksAfterShutdown
|| task.getDelay(NANOSECONDS) <= 0);
}
void ensurePrestart() {
// 获取当前工作线程的数量。
int wc = workerCountOf(ctl.get());
// 增加工作线程。
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
addWorker()方法主要作用是创建Worker对象,每个对象关联一个线程,不断从工作队列中取出任务并执行,详细解析可以查看《ThreadPoolExecutor》一文,不再赘述。
DelayedWorkQueue
当Worker对象被创建后,就会不断的从工作队列中取出任务执行,下面我们看下工作队列DelayedWorkQueue的实现。
DelayedWorkQueue是ScheduledThreadPoolExecutor的一个静态内部类,其结构如下。
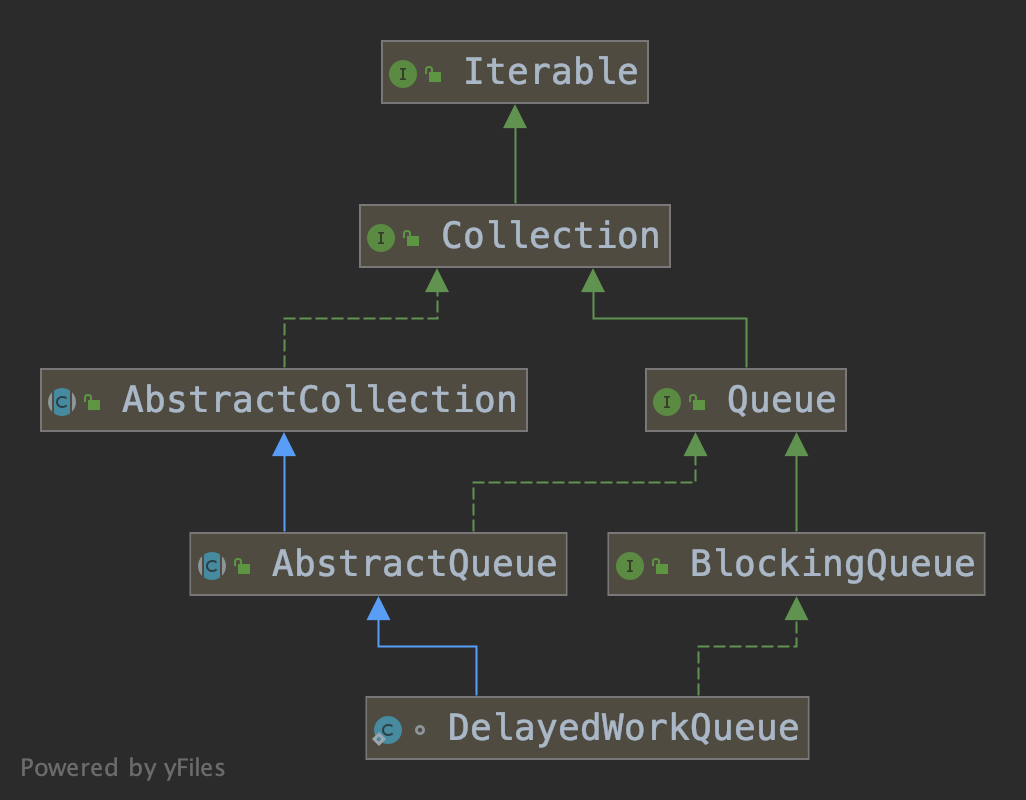
offer(Runnable)
offer()方法用于把一个Runnable对象插入到队列中。
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = size;
// 队列满了就进行扩容。
if (i >= queue.length)
grow();
size = i + 1;
// 如果队列是空的,那么就设置为队列中的第一个元素。
if (i == 0) {
queue[0] = e;
setIndex(e, 0);
} else {
// 插入元素并调整二叉堆。
siftUp(i, e);
}
// 如果队列中的第一个元素就是插入的元素,向消费线程发送信号。
if (queue[0] == e) {
leader = null;
available.signal();
}
} finally {
lock.unlock();
}
return true;
}
队列的底层数据结构是一个RunnableScheduledFuture<?>[]类型的数组,初始容量是16,基于该数组建立了一个二叉堆。
private static final int INITIAL_CAPACITY = 16;
private RunnableScheduledFuture<?>[] queue = new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
siftUp()方法会把元素插入到队列中,并调整元素的顺序以满足二叉堆的定义。
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
// 二叉堆父节点的索引。
int parent = (k - 1) >>> 1;
// 父节点。
RunnableScheduledFuture<?> e = queue[parent];
if (key.compareTo(e) >= 0)
break;
// 如果key小于父节点,那么交换这两个节点。从这里看出构建的是小顶堆。
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
这里参数key的实际类型是ScheduledFutureTask,它是ScheduledThreadPoolExecutor的一个内部类,它的结构如下。
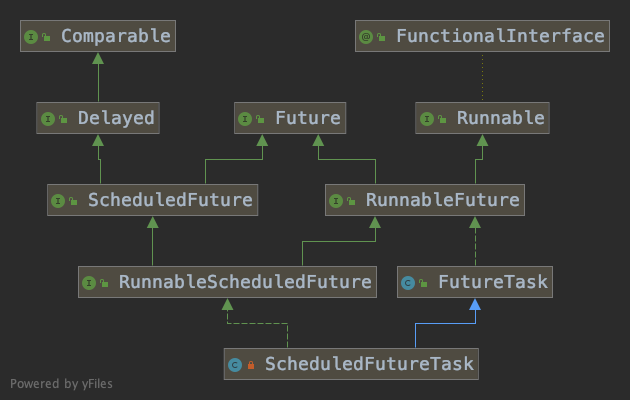
调整元素顺序时用到的compareTo()方法如下所示。
// java.util.concurrent.ScheduledThreadPoolExecutor.ScheduledFutureTask#compareTo
public int compareTo(Delayed other) {
if (other == this)
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
// 比较时间。
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
// 时间相等则比较序号。
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
}
首先比较两个任务的执行时间,如果执行时间相等再比较任务序号的大小,所以位于二叉堆堆顶的任务就是最先执行或者序号最小的任务。
take()
take()方法用于从队列中取出一个任务,如果队列为空,那么当前线程会被阻塞。
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
// 如果队列为空,则等待offer()方法中发出的信号。
if (first == null)
available.await();
else {
// 任务设定的执行时间与当前时间的差值。
long delay = first.getDelay(NANOSECONDS);
// 如果时差小于等于0,那么就从队列中取出任务。
if (delay <= 0L)
return finishPoll(first);
first = null;
// 如果leader线程存在,那么当前线程进行阻塞。
if (leader != null)
available.await();
else {
// 否则把leader设置为当前线程。
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 等待指定的时间。
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
// 更新队列中元素的数量。
int s = --size;
// 获取队列的最后一个任务。
RunnableScheduledFuture<?> x = queue[s];
queue[s] = null;
// 如果队列不为空,那么调整二叉堆。
if (s != 0)
siftDown(0, x);
setIndex(f, -1);
return f;
}
// 该方法的效果是把key放到数组中索引为k的位置,并从该位置向下调整二叉堆。
private void siftDown(int k, RunnableScheduledFuture<?> key) {
int half = size >>> 1;
while (k < half) {
// 左子节点。
int child = (k << 1) + 1;
RunnableScheduledFuture<?> c = queue[child];
// 右子节点。
int right = child + 1;
// 如果右子节点存在并且左子节点大于右子节点,那么把变量c指向右子节点,即变量c指向左右子节点中较小的那个。
if (right < size && c.compareTo(queue[right]) > 0)
c = queue[child = right];
// 如果key小于等于c,说明key小于等于左右两个子节点,不需要再向下进行调整,跳出循环。
if (key.compareTo(c) <= 0)
break;
// 否则继续进行调整。
queue[k] = c;
setIndex(c, k);
k = child;
}
queue[k] = key;
setIndex(key, k);
}
Leader线程
take()和offer()中有一个比较特别的leader字段,它的目的是保证只有一个线程会等待定时任务的执行,也就是take()方法中以下的语句只有一个线程会执行。
available.awaitNanos(delay);
与此同时,其它方法都会执行available.await()进入阻塞。这样设计的目的是减少不必要的定时等待。
scheduleAtFixedRate(Runnable, long, long, TimeUnit)
该方法用来执行周期性的任务,其实现和schedule()方法最大的区别是创建ScheduledFutureTask对象时设置了它的period字段表示任务的执行周期。
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0L)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(period),
sequencer.getAndIncrement());
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
下面是ScheduledFutureTask类的run()方法,线程池从工作队列中取出任务后就会调用该方法。
// java.util.concurrent.ScheduledThreadPoolExecutor.ScheduledFutureTask#run
public void run() {
// 检查线程池状态。
if (!canRunInCurrentRunState(this))
cancel(false);
// 如果不是周期性任务,调用基类的run()方法。
else if (!isPeriodic())
super.run();
else if (super.runAndReset()) {
// 如果是周期性任务,需要设置下一次的执行时间并重新放回工作队列。
setNextRunTime();
reExecutePeriodic(outerTask);
}
}
// java.util.concurrent.ScheduledThreadPoolExecutor#reExecutePeriodic
void reExecutePeriodic(RunnableScheduledFuture<?> task) {
if (canRunInCurrentRunState(task)) {
// 放回工作队列
super.getQueue().add(task);
if (canRunInCurrentRunState(task) || !remove(task)) {
ensurePrestart();
return;
}
}
task.cancel(false);
}
scheduleWithFixedDelay(Runnable, long, long, TimeUnit)
该方法也是用来执行周期性的任务,它和scheduleAtFixedRate()的区别是scheduleWithFixedDelay()下次执行任务的时间是以上一次任务执行结束的时间为基准计算的,比如从10:00开始执行一个任务,任务执行本身耗时1分钟,任务执行间隔1分钟,那么下次任务执行时间就是10:02,而scheduleAtFixedRate()则是固定的间隔,比如从10:00开始执行一个任务,任务执行间隔1分钟,那么下次任务执行时间就是10:01,任务本身的耗时并不会影响它的执行周期。
scheduleWithFixedDelay()的实现原理也和scheduleAtFixedRate()类似,区别是在创建ScheduledFutureTask对象时,其period字段是负值,注意下面代码中的-unit.toNanos(delay)。
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0L)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
-unit.toNanos(delay),
sequencer.getAndIncrement());
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
当给周期性任务设置下一次的执行时间时,对scheduleAtFixedRate()方法而言就是在任务的当前执行时间上再加上任务执行周期,对于scheduleWithFixedDelay()方法则是当前时间加上任务执行周期。
private void setNextRunTime() {
long p = period;
if (p > 0)
// scheduleAtFixedRate()的分支。
time += p;
else
// scheduleWithFixedDelay()的分支,注意:这里p小于0。
// 得到的结果是当前时间加上任务执行周期。
time = triggerTime(-p);
}